



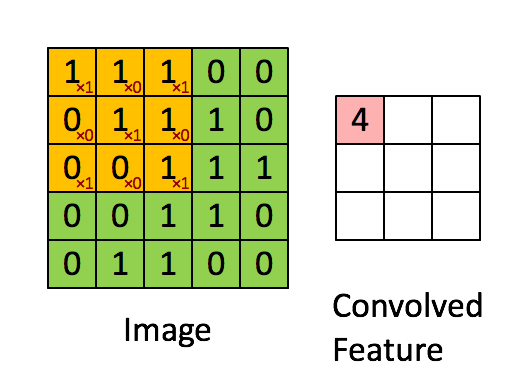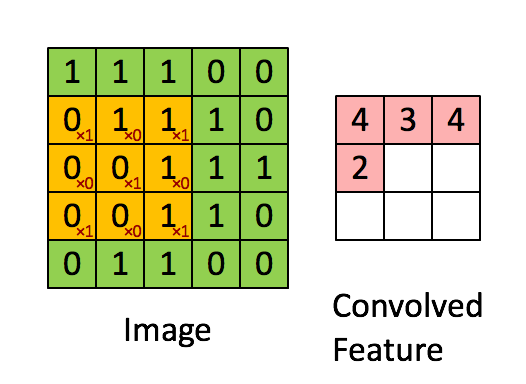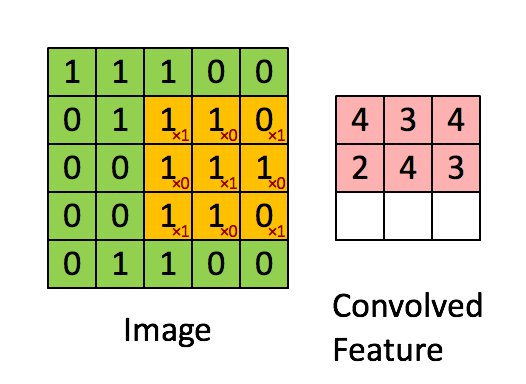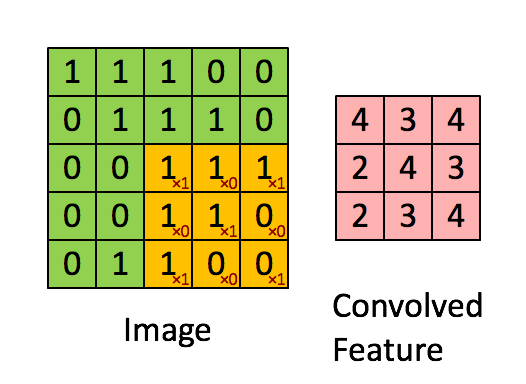
Senast redigerat






I just love the fact that there is a global integer variable named 'i'. Just think, you will never need to declare your loop variable again!
To avoid collisions where a loop that uses 'i' calls another function that loops with 'i', be sure to stack 'i' and restore it when your function exits.
