But there is a thing called too less ram.. Jag skulle ha skaffat mer till denna.
Hur många newbies som använder ett program är irrelevant. Man ska se på skaran användare som tjänar prestanda på att betala 10 000kr extra på att välja HEDT istället för 1950X i matlab och det är inte många.
Borde inte spelbenchmark med mycket kommunikation mellan kärnorna vara ett dåligt exempel för de flesta program? De flesta problem som tar tid är när trådar arbetar i princip helt oberoende av varandra och det intressanta är hur de kan dela olika io-resurser av olika slag.
Sedan att linux kan hantera si och så många kärnor, visst dockers blir vanligare, men folk som har bättre processorer har ofta igång x antal windows samtidigt. Säg att man kör 10st, ger alla 8st kärnor var (ej dedikerade) så snurrar windows på bra.
Visst när dockers blir bättre så kommer säkerligen fler våga köra mer på samma windows, men nu splittrar folk och kör en sak på varje operativsystem. Ska man ha en databas, ja lägg den på en egen maskin osv. Installera databaser och annat på samma os blir bara ett kladeverk i windows och det är stora problem när det krånglar.
Finns rätt mycket bevis på att Windows får problem när antal kärnor ökar. Till viss del kompenserar Microsoft detta i sina servervarianter, i dessa finns en del inställningar och val som försämrar egenskaperna som desktop OS men förbättrar egenskaperna som server OS. Övergripande är det samma gamla vanliga avvägningar, man offrar svarstid och latens (som båda är kritiska för trevlig interaktiv användning) för högre total kapacitet (som oftast är att föredra för servers).
Syns rätt bra om man jämför modellerna från R5-1500X upp till TR-1950X i Geekbench. Upp till 4-6 kärnor är det hyfsat likvärdiga genomsnittliga resultat på Windows och Linux, från 8 kärnor och uppåt börjar Linux dra ifrån rätt ordentligt.
Titta i resultatdatabasen, första ~30 sidorna för toppresultat i "mult-core" är uteslutande Linux-maskiner. Finns långt fler Windows-resultat för de maskiner som ger toppresultat (multi-socket Xeon system).
Min oklockade R5-1600 med 2933 MT/s minnen körandes Ubuntu server drar jämnt med max-klockade R5-1600/1600X utrustade med betydligt snabbare RAM körandes Windows. Då är ändå Linux fördel rätt liten vid 6C/12T jämfört med 8C/16T och högre.
Geekbench har gått från att vara ett skämt som benchmark i tidigare versioner till att faktiskt vara en av de bättre indikatorerna på desktop prestanda. Tidiga versioner skala löjligt bra med CPU-kärnor, fick orimligt bra prestanda på väldigt enkla CPUer (ska man tro GB3 är många telefoner snabbare än x86 laptops) etc. Detta då man hade uteslutande micro-benchmarks som fick plats i L1$ och man testade allt för specifika saker.
GB4 använder sig i stället av "riktiga" program och "riktiga" bibliotek med någorlunda representativt storlek på data (man gör fortfarande vissa kompromisser på denna punkt för att kunna köra på alla typer av system).
Tar vi Matlab specifikt, varför ska man betala 10000 extra? Till att börja med presterar SKL-X faktiskt så pass mycket bättre att pris/prestanda är faktiskt bättre på 7980XE än på 1950X i just detta fall. Men SKL-X är så pass mycket starkare på just den här typen av uppgifter att det räcker med 7900X för att kliva förbi 1950X (faktum är att i7-8700K drar jämnt med 1950X här och i7-8700K blir demolerad av SKL-X p.g.a. att den senare har AVX512).
SGEMM och i något mindre utsträckning SFFT deltesterna är en bra indikation på vilken relativ prestanda man kan förvänta sig i vetenskapliga applikationer där problem hanteras via matriser (vilket är de flesta). Finns en de-facto standard här i form av BLAS (Basic Linear Algebra Subprograms), finns sedan en rad implementationer av detta och i de program jag använt är det möjligt att själv välja vilket bibliotek man vill köra. Det som typiskt presterar bäst är Intels MKL (fungerar även på AMDs aktuella CPUer).
Spelbenchmarks är inte en perfekt match, handlar ju alltid om att göra förenklingar när man benchmarkar. Om något är spel en överskattning av hur pass väl CPU-kärnor kan nyttjas av desktop-program i genomsnitt.
Att CPU-kärnorna kommunicerar en hel del är dock väldigt typiskt för desktop-program, dessa är nästan aldrig "embarrassingly parallel". Desktop-program är normalt interaktiva (så latens är viktigare än beräkningskraft) och de har ofta hög andel I/O kontra beräkningar.
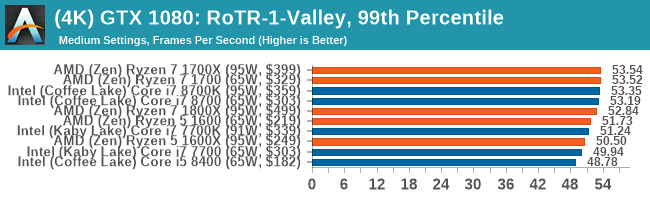
Skulle säga att denna graf

är betydligt mer representativ för "generell desktop-prestanda" än de man får från många andra håll där allt för stor andel av testerna är rendering och liknande (som skalar i princip helt perfekt).
TechPowerUp har med Cinebench, VeraCrypt, 7-zip och liknande. Men man har också med Photoshop, virus scanning (typfallet på kort I/O stint, lite CPU-crunch, repeat -> korta svarstiden är långt viktigare än total kapacitet), Excel etc.
Jag tror att skaran som väljer HEDT är ganska stor, kanske 10 % enligt en studie nämnd i
https://www.extremetech.com/computing/255122-european-retaile...
Det är för stort nog för att inte glömma bort. Notera att 1950X är större än 7900X.
https://www.extremetech.com/wp-content/uploads/2017/09/CPUsPerMonth.png
@Yoshman, grymt med Stan. Hade inte hört talas om det, men använder ofta Bayesianskt (anropade binärer från R med system). Nu kanske man kan finsnickra själv framöver; har redan hittat ett exempel jag vill spinna vidare på. Tack!
Har du något uppfattning om varför spel och bayesianskt samvarierar? Har du siffror eller en hunch? Priors och rekursivitet finns ju dessutom inte hos spel. Inser inte att det finns likheter.
Spel och Monte Carlo simulering (Bayesiansk statistisk inferens) har i princip inget gemensamt. Jag som var otydligt där.
Spel-benchmarks (i lägen där GPUn är borta ur ekvationen) är en hyfsad indikator på hur systemet kommer hantera en lång rad typiska desktop-fall som är optimerade för att använda flera CPU-kärnor. Detta då desktop-program, likt spel, nästan alltid kräver en hel del synkronisering mellan kärnor.
Monte Carlo simulering är ett exempel på där man i praktiken kan använda hur många kärnor som helst! Det är ett "embarrassingly parallel". Så perfekt match för HEDT-plattformen då?
Här är min ståndpunkt att dels är detta ett fall som ännu bättre hanteras av server-plattformar med lite lägre klockade CPUer, fast fler kärnor. Och detta är också ett fall där flera sockets är ett icke-problem, det är till och med en fördel då man kan sprida ut TDP över flera kretsar.
Men då det är ett "embarrassingly parallel" problem finns väldigt ofta än ännu bättre lösning, så även här. HEDT kanske kan ge upp mot x10 jämfört med en billig desktop CPU, grejen är att GPGPU kan ge x100...
Och det är huvudproblemet jag har med hela HEDT-segmentet: vem är den optimerad för? Typiska desktop-laster rullar snabbare på i7-8700K (den har mer lämpad cache-policy för detta, den har lägre latens mot cache och RAM, den har högre prestanda per kärna). I andra änden har vi de fall som skalar extremt väl med kärnor, handlar det om uppgiftsparallellism är server-plattformarna bäst lämpade och handlar det om dataparallellism är väldigt ofta GPGPU bäst lämpad men finns vissa fall där SIMD (d.v.s. SSE/AVX) fungerar bättre.
Är också helt övertygad om att TR säljer bättre sett till antal jämfört med SKL-X. Men än mer övertygad om att HEDT står betydligt närmare för 1 % av försäljningen än 10 %. Titta på AMDs och Intels senaste kvartalsrapporter, AMDs kombinerade försäljning av CPUer (exklusive Epyc) och GPUer är nästan exakt en tiondel av Intels kombinerade försäljning av CPUer (igen exklusive Xeon då detta redovisas separat).
~70-75 % av alla x86 desktop-CPUer som säljs går idag till bärbara enheter. Om nu AMD har ~50 % av de kvarvarande 25-30 % och det skulle utgöras av > 5 % TR, hur förklarar man då 1/10 fördelningen i omsättning och att Intel har dubbla bruttomarginalen jämfört med AMD (bruttomarginalen för TR-1950X måste rimligen vara klart högre än i7-7700K, annars är det någon som ska avgå med omedelbar verkan)?
Och om HEDT vore ekonomiskt viktigt, borde inte Intel reagera på att TR av allt att döma säljer bättre än SKL-X? Är inte en sannolikare förklaringen att HEDT-marknaden är ur ekonomiskt synvinkel helt irrelevant, men den är viktig ur PR syfte.
Ur PR syfte räcker det med att "vinna" benchmarks hos de stora teknikwebbplatserna. Vad 7980XE kostar är i det läget irrelevant, räcker med att den är med i testresultaten.
Det går självklart att hitta enstaka nischer när HEDT är det optimala valet, ett exempel jag ser för SKL-X är vissa typer av vetenskapliga beräkningar då det finns områden som inte skalar bra över CPU-sockets (egentligen skalar inte bra över NUMA-zoner) men ändå skalar lysande med RAM-bandbredd, SIMD och kärnor. Men på det stora hela är det en rätt smal nisch... Förstår också exakt hur problem ska vara beskaffade för att vara optimala för TR, men har kan jag liksom inte ens komma på fall utanför typiska server-laster.
Det betyder inte att HEDT är en dålig desktop CPU, tvärt om ligger dessa nära toppen. Men för majoriteten av alla desktop-laster finns det ännu snabbare (och väsentligt billigare) alternativ.
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer