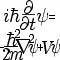Jag hade länge fått för mig att M1 hade högre teoretisk kapacitet mot RAM än andra PC. Nu när fler detaljer börjar komma fram (då folk själv kan testa/analysera M1) har det framkommit ät det "bara" handlar om dual-channel LPDDR4X-4266 MT/s. Det är som du korrekt påpekar totalt 128-bitars minnesbuss (x2 64-bitar per kanal).
Men finns ändå unika delar i M1. Dels har du det @loevet nämner ovan, M1 består av flera xPU-kretsar som alla delar samma minnespool. Att dela minne på detta sätt har naturligtvis uppenbara nackdelar i att alla delar bandbredden, dual-channel LPDDR4X-4266 MT/s ger ändå mer bandbredd än de flesta PC-system (finns ett par Tiger Lake U och Zen2 baserade bärbara som också använder sådant RAM).
Den stora vinsten är att delat minne mellan flera xPU-kretsar betyder att ingen I/O behövs för att flytta data mellan dessa, det sparar ström och framförallt minskar det kraftigt latensen att accelerera specifika jobb på den krets mest lämpad för uppgiften. MacOS har nu både ramverken och kislet för att utnyttja homogena system, något som gör att de flesta traditionella benchmarks underskattar prestanda hos M1 för benchmarks är typiskt designade för Windows som saknar både ramverken och HW.
Fast även om man enbart zoomar in på CPU-delen finns unika delar runt bandbredd mot RAM, något som bl.a. Anandtech nämnt
One aspect we’ve never really had the opportunity to test is exactly how good Apple’s cores are in terms of memory bandwidth. Inside of the M1, the results are ground-breaking: A single Firestorm achieves memory reads up to around 58GB/s, with memory writes coming in at 33-36GB/s. Most importantly, memory copies land in at 60 to 62GB/s depending if you’re using scalar or vector instructions. The fact that a single Firestorm core can almost saturate the memory controllers is astounding and something we’ve never seen in a design before.
Testade min 3900X lite snabbt, den kan också utnyttja hela RAM-bandbredden från CPU-delen. Skillnaden är att det krävs 6-7 kärnor för att man riktigt ska kunna maxa, en kärnan utnyttjar i fallet jag testade (minnestestet i Sysbench, där handlar det också om rå minneskopiering) mindre än 10 GB/s och det skalade i princip linjärt till två kärnor (efter det faller ökningen av allt mer per kärna till man når maxkapacitet).