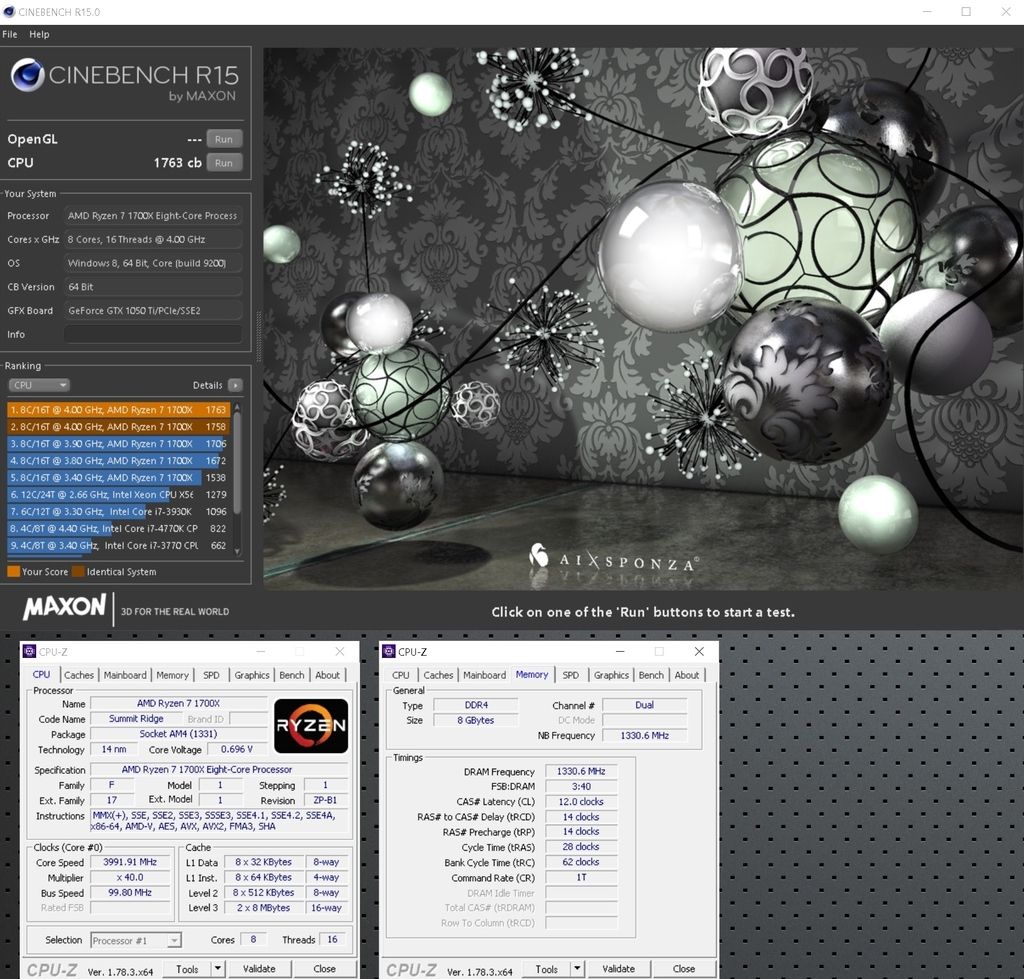
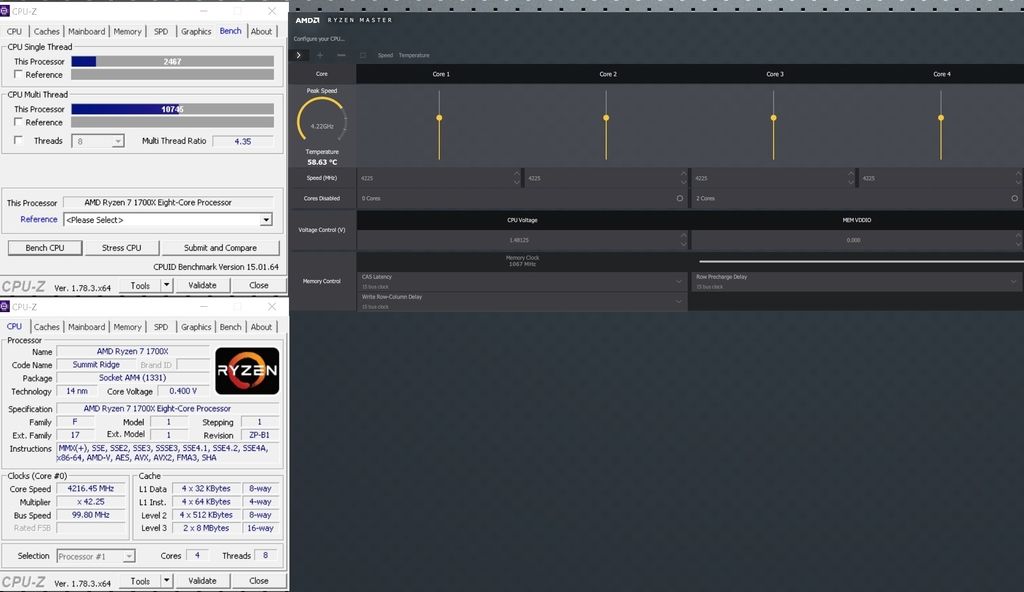
Tills detta är åtgärdat är det nog så att Windows 10 är en inte helt optimal plattform att jämföra IPC. Jag gissar på delvis omgjorda reviews inom några veckor...
https://www.youtube.com/watch?v=kr6CYZmjKcA
https://www.youtube.com/watch?v=v-D9uDeOvtQ
https://www.youtube.com/watch?v=U9DE83lMVio
https://www.youtube.com/watch?v=CXDxZxFqhdY
Från anandtechs updaterade recension:
Några kontrollfrågor bara:
Du har tittat på de videon du länkar va? Vad ska de visa?
CS:GO - Win7 ligger absolut högre, men är väldigt hög FPS och CPU-användningen visar att det främst är en CPU-tråd som är hårt lastad.
BF1 - fick titta flera gånger, men här presterar väl ändå Win10 konsekvent bättre? Och BF1 brukar framhållas som ett spel där flera kärnor kommer väl till pass.
TombRaider (2013) - Win7 ligger absolut högre, även om detta spel är bättre än CS:GO på att utnyttja kärnor så är det ändå rätt dåligt på att sprida last och FPS på ~400 strecken (knappast väl testat på någon plattform)
Doom (OpenGL) - är ju helt jämnt skägg, detta är ju ett spel som kan dra nytta av hyfsat många kärnor.
Så är syftet med dessa länkar att visa: Win10 fungerar absolut väl med titlar som faktiskt använder relativt många kärnor eller var syftet att visa att Win10 är sämre i gamla spel? Vet vi hur Intel presterar i CS:GO och TR 2013, kanske är så att dessa titlar (som båda släpptes innan Win10) generellt presterar bättre på Win7.
Och anta nu att det är något fel på schemaläggaren i Win10, känns det då sannolikt att Win7 på något magiskt sätt är optimerad för Zen? Enligt PC Perspective säger ju AMD själva att de INTE anser att det finns något problem med hur Windows 10 hanterar Ryzen. AMDs fokus ligger i stället på att jobba med spelutvecklare för att göra speciella optimeringar för Ryzen, något som faktiskt är möjligt och något man borde redan ha erfarenhet kring då PS4/XBO också har en CPU som består av två fyra-kärnors-delar som inte delar cache.
Specifikt står detta i artikeln
"I have been told from high knowledge individuals inside the company that even AMD does not believe the Windows 10 scheduler has anything at all to do with the problems they are investigating on gaming performance."
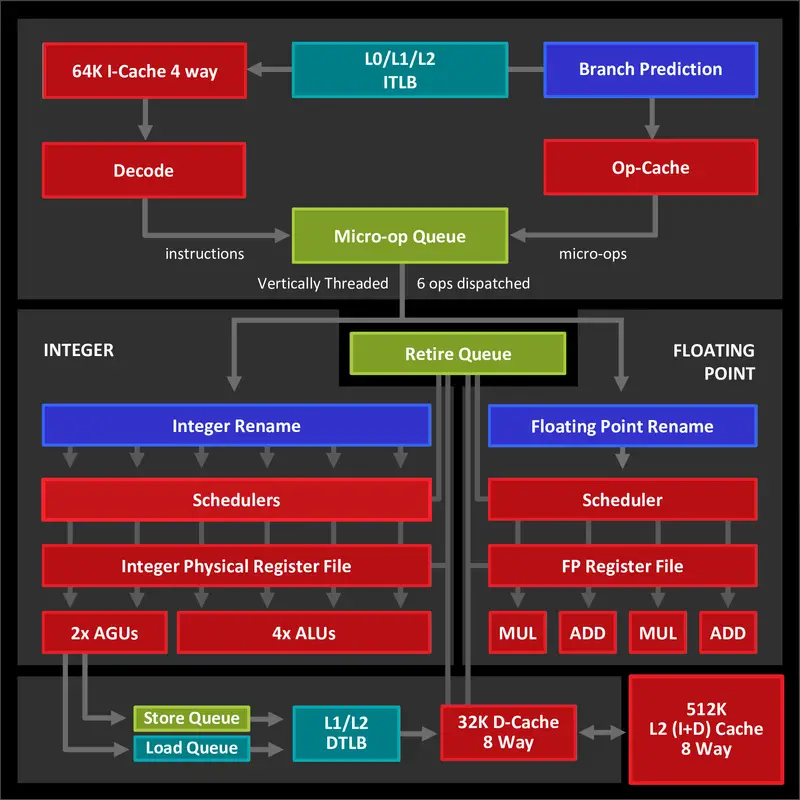
Och till de som fortfarande tror att man kan göra en generell optimering för hur schemaläggning över CCX-gränsen ska fungera: hur många OS-schedulers har du skrivit? Tänk att du ska skriva en, hur ska du som OS-utvecklare kunna avgöra om det optimala är att sprida över CCX eller hårt hålla saker på samma CCX även fast alla kärnor har en tråd aktiv på alla fysiska kärnor? Det är omöjligt att ge ett generellt gångbart svar på detta, det beror på vad trådar gör och den enda som har den informationen är applikationsutvecklaren.
OS-utvecklar har tänkt på detta fall. Det är fullt möjligt för applikationer att göra override på hur trådar schemaläggs, är en standardfunktion i både Windows och Linux.
Ergo, sprida eller inte sprida över CCX är INTE ett beslut som bör tas av OSet. På vilket sätt är då Windows 10 scheduler fel idag?
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer