Skrivet av Enigma:
Syntetiska tester? Handbrake är en sak då det är en typisk praktisk tillämpning när man kör encoding av videomaterial, annars är dom allra flesta överens om att dom IPC ökningar vi sett i typiska applikationer blygsam hittills mellan generation 2 till 6. ( för att inte nämna dom som köpte 2600K och varför dom inte behövt byta på "evigheter"). Dessutom så har 4790K 500Mhz högre turbofrekvens än 3770K som jämförs i testet du valt att länka till. Det behövs verkligen ingen upplysning om vad som skiljer IB och Haswell åt i 95% av relevanta applikationer.
Har nog aldrig sett någon tidigare försökt hävdat att kompilering är ett syntetiskt test... Skulle jag bara få AMD att publicera ett enda test för Zen så vore det just hur den står sig i kompilering jämfört med andra modeller. Kompilering är så pass heltäckande att det inte går att "fuska" på något annat sätt än att helt enkelt göra en bra CPU-design. Sett flera göra anmärkningen att SPECInt är totalt värdelöst så när som på kompileringstestet då i princip allt annat går att göra speciallösningar för på olika sätt.
Även om Linpack är ett benchmark så skulle jag inte kalla de för syntetiskt. Man använder just detta test för att designa superdatorer för HPC då det är väldigt representativt för verklig prestanda. Sedan är resultaten jag postade tagna med Intel MKL, ett bibliotek som många använder i applikationer som jobbar med matriser eller signalbehandling.
Sunspider är absolut ett dåligt syntetiskt test om man ser det som en test av webbläsarprestanda. Sunspider, Octane samt Kraken är däremot alla riktigt bra tester för att ge en vink om generell prestanda i applikationer skrivna i JavaScript/NodeJS vilket är en allt viktigare plattform på servers och i "molnet".
Angående turbofrekvensen, jämför då 3770K (3,9 GHz turbo) och 5775C (3,7 GHz turbo) alt. kompensera för frekvensen, det är >10 % högre IPC. L4-cachen i 5775C har i princip noll effekt i dessa tester (snarare negativ då 2 MB av L3 används för snoop-information för L4 så man har bara 6 MB L3 mot 8 MB på 3770K).
Skrivet av Enigma:
I servermiljö så har Haswell större chans att sträcka på benen ja. Jag tror dock att AMD har betydligt mindre bekymmer att lyckas på servermarknaden med Zen än på konsumentmarknaden vilket var det jag mest inriktade mig på.
Det måste vara viktigare för AMD att lyckas i datacenter och servers än att göra det på skrivbordet med Zen då det förra är både mer lukrativ och till skillnad från den senare fortfarande en växande marknad.
Skrivet av Enigma:
På den tiden snackar vi skillnader och utveckling på området. Dom IPC ökningar som gjorts sista 10 åren på x86 arkitekturer är bara pinsamt och finns inget annat än att bara inse när man kan blicka tillbaks på historiens konkurrens som vi hade mellan bolagen. Det var kul ända tills hotet från AMD blev så stort att Intel fick muta sig bort från dom. Kontentan: historiskt bötesbelopp i domstol.
IPC ökning de senaste tio åren är högre än de tio år du hade innan, det som ökade prestanda innan dess var nästan uteslutande högre frekvens. Och IPC ökningen de senaste tio åren är bara pinsam om man använder t.ex. spel som måttstock då dessa, men där är ju inte CPU-delen flaskhals så en värdelös måttstock.
Skrivet av Enigma:
AMD har alltid kört 64Kb L1 instruktionscache och nu har man ökat associativiteten med det dubbla. Det kan mycket väl vara gynnande för denna typ av arkitektur att ha en större L1i cache. Bara för att Intel kör med 32Kb så ska det vara skrivet i sten att en helt annan arkitektur ska bli lidande av det? Ja lika mycket eller lite kanske Skylake blev lidande utav att få hälften av associativiteten på L2 cachen jämfört mot tidigare generationer. Det som är min poäng.
Skylake har högre bandbredd mot L2, vilket till viss del kan kompensera för lägre associativiteten.
Här är ändå min huvudpoäng: visst kan det fungera helt OK med att inte kunna köra TLB uppslagning parallellt med L1I$, men resultatet är en högre effektiv latens jämfört med huvudkonkurrenten.
Skrivet av Enigma:
Zen har en asymmetrisk design utav load/store, så det räcker förmodligen med 2 AGU's. Förhoppningsvis har AMD räknat på det som en del av balansen med tanke på infon som man nu stenhårt gått ut med både tidigt och officiellt.
AMD sa att detta skulle vara väl uppmätt och därav det designvalet, och vi ser ju då 1x16Byte store per cykel respektive 2x16-Byte load. Hurvida det stämmer i verkligheten är ännu en sak vi får vänta och se.
Detta ska bli intressant att se effekten av. AMD har aldrig tidigare haft en x86 modell där inte load/store vs ALU varit 1:1. Intel har så vitt jag kan dra mig till minnes haft en modell med 3:2 splitt av ALU vs load/store (PII till Pentium M), annars har det varit 1:1.
Effekten av detta är i alla fall garanterat noll i tester som Cinebench och Blender då båda dessa är begränsade av att man endast har två flyttalspipeliens som kan göra add/mul. Framförallt Cinebench verkar väldigt hårt begränsad av detta då den får väldigt liten boost av SMT.
Lite intressant att man ändå har 2x load och 1x store kapacitet. Gissningsvis har man detta för att kapa toppar efter en cache-stall för designen kan inte upprätthålla mer än totalt två minnesoperationer per cykel.
Varför känns 2:1 lite klent? Tänk bara på denna C++ rad
Finns rätt många rader med motsvarande logik i typiska program, vad behövs för att köra detta?
En load, en addition och en store, om vi antar att foo inte har offset noll behövs också en adressberäkning (lea). Gissar att lea även kan köras av ALU-pipes, såg det nämnas någonstans att just denna instruktion kan hanteras i AGU (vilket även är fallet på Intel där man till och med har en separat pipeline för adressberäkningar).
Min gissning är att första förändringen man kommer göra på Zens pipeline i framtiden är att addera en ren store-pipeline. Två pipelines som kan göra load/store plus en som kan göra store matchar den design de redan har mot cache och en ren store-pipeline är mycket enklare då store:s inte behöver "snoopa" andra kärnors "store-buffer".
Skrivet av Enigma:
Har du någon mer källa på det där än bara ryktet? Så vet jag vet så var Keller väldigt inne i just Zen sedan det var en nystart sedan K7/K8 tiden.
Såg det på ett par forum, det är ett rykte så "källa" blir ju lite svajigt. I ett av fallen var kommentaren från någon som hävdade att hen vid tillfället jobbade på AMD med just detta.
Sedan kanske värt att reda upp lite kring vad Keller faktiskt gjort: han har rimligen inte designat K7 då han började ungefär ett år innan den kretsen först lanserades. Han jobbade faktiskt bara ett år på AMD under den tiden, då var han chefsarkitekt för K8 samt medförfattare av AMD64. Första K8 modellen lanserades två-tre år efter att han slutande, vilket stämmer bra med ryktet att hans arbete med första generations Zen redan var färdigt när han slutade förra året.
Skrivet av Enigma:
Vid den tidspunkt då AVX eventuellt skulle normaliseras som den typ av flyttal som används hårt på konsumentmaskiner så är både Zen och Haswell dammsamlare på hyllan.
Haswell kommer vara fyra år gammal när Zen lanseras, anser du att det är en krets som är obsolete idag?
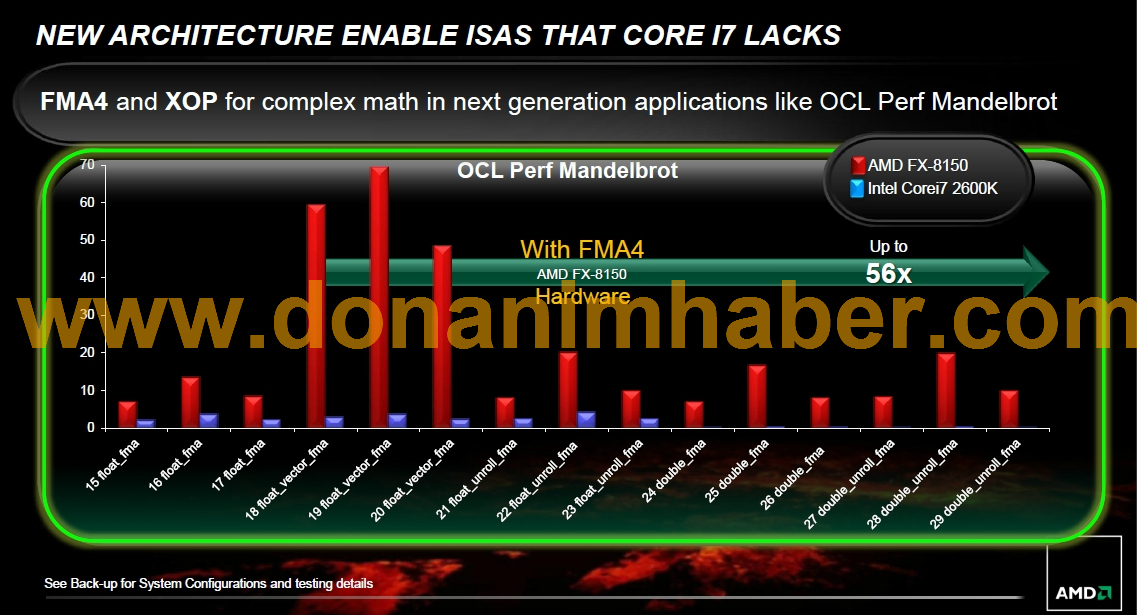
Som jag skrev innan, AVX är irrelevant för applikationer på skrivbordet och många serverapplikationer. Men program som Matlab och andra där man jobbar mycket med matriser har absolut stöd för AVX redan. Anledningen är att man får en signifikant boost av prestanda så det är värt besväret. På det stora hela är det ändå nischmarknader, AMD kan inte sikta på allt direkt med Zen och flyttalsapplikationer som kan vektoriseras är en akilleshäl för första Zen-generationen.
Skrivet av Enigma:
L3 cachen och dess interna bussarkitektur vet man väldigt lite om än så länge, och jag gissar på att detta är en typisk detalj som kommer att uppenbara sig mer på HotChips.
Blir intressant att se hur den skalar i frekvens.
Nu i tråden, gärna lite mer om Zen, och mindre om Intel.
Det man undrar om Zens L3 är om det är en LLC som täcker alla kärnor eller om det är ett sektion per fyra kärnor som die-shot pekar mot... Detta är relevant av flera skäl.
Om alla kärnor delar en LLC kan denna också används som "snoop-filter" vid cache-missar, man kan ha en bit per kärna som talar om huruvida det minnet någonsin varit cachat på en viss kärna. Det kan ge "false-positivs" men om biten inte är satt för någon annan kärna än del lokala så vinner man latens då man inte behöver invalidera andra kärnors L1D/L2.
Vidare är en LLC som delas av alla kärnor kritiskt för att relativt effektivt kunna kommunicera mellan kärnor. Jaguar-kretsen som sitter i PS4/XBO är väldigt asymmetrisk på denna punkt då det finns två grupper om fyra kärnor som delar L2 men de två grupperna har ingen delad cache. Det skiljer en ungefär en faktor tio mellan att peta på en cache-line som ligger inom samma block (som delar L2) och en som används av någon kärna i det andra blocket.
För servers är det ett mindre problem då man typiskt har väldigt många saker som sinsemellan är oberoende, så hög latens på det sättet är ingen katastrof. De applikationer på skrivbordet som faktisk kan använda flera CPU-trådar, t.ex. spel, måste tänka rätt mycket på att hålla allt som behöver dela något inom kärnor som delar LLC.
Om det är en L3 per fyra kärnor så skulle jag säga att den fyrkärniga Zen-modellen känns som det vettigare valet på skrivbordet. Eller ja, den är nog det vettigare valet oavsett bra den kan klockas högre då väldigt nära 100 % av alla desktopanvändare klarar sig mer än nog med fyra kärnor (majoriteten har absolut inga problem med två kärnor + HT även om man gör rätt avancerade saker).