

Progblemet #6 - Parallel Fibonacci
Tänkte titta på en väldigt enkelt funktion som har en del intressanta egenskapar, nämligen den naiva rekursiva implementationen av beräkning av Fibonacci serien.
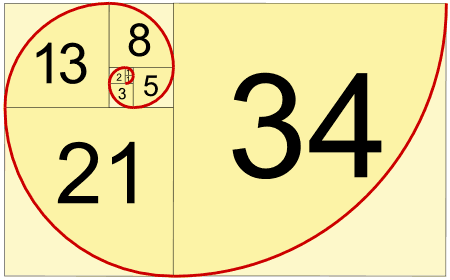
En egenskap för denna serie är att den förekommer ofta i naturen, radien på cirklarna i snäckors skal följer denna serie, många känner säkert igen denna bild där man drar en krökt linje från hör till hör av kvadrater där längden på sidorna följer Fibonacci serien.
Serien definieras av
F(0) = 0
F(1) = 1
F(n) = F(n-1) + F(n-2)
Detta kan implementeras på följande sätt i t.ex. Python
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n-2)
Har kanske vissa har invändningar då detta sätt att implementera denna serie må vara exakt från den matematiska definitionen, men det är extremt ineffektivt (går att lösa i linjär tid). Jag vet men att göra en effektiv implementation är inte poängen här. En trevligt egenskap med denna implementation är att den innehåller massor med möjlighet till parallellism.
Men vad betyder egentligen parallellism? Många har ju hört talas om Ahmdal's lag och kanske även Gustafson's lag. Båda dessa lagar är helt korrekta, Ahmdal's lag gör det möjligt att beräkna den teoretiskt maximala hastighetsökning man kan få givet ett problem av fix storlek och att man vet hur stor del som kan köras parallell samt seriellt. Gustafson's lag är i grunden samma sak men den antar i stället att den seriella delen av ett problem är fixerad och lagen säger hur stort problem man måste lösa för att nå en given grad av vinst från ett givet antal CPU-kärnor.
Problemet med båda dessa lagar är att de inte säger något om vilken parallellism ett givet problem faktiskt har. Och åter igen, vad är parallellism?
För att definiera det begreppet måste man först införa två andra begrepp
work är totala mängden arbete som måste utföras för att lösa ett problem
span är den längsta vägen igenom problemet som måste lösas steg för steg
För att lösa Fibonacci för talet 4 får man då denna graf

Totala mängden arbete, work, är lika med antalet "prickar" medan span är den numrerade serien. Parallellism är kvoten mellan work / span och beskriver den teoretisk maximala hastihetesökningen man kan få genom att lösa detta problem med en oändlig mängd CPU-kärnor. Vill man i stället veta den teoretisk maximala ökningen givet C CPU-kärnor kan man kombinerar denna med Ahmda's och lösa ut "speedup" variabeln.
För detta progblem räcker det att parallellismen för den naiva implementationen av Fibonacci är ungefär 1.6^n/n (1.6 upphöjt till talet man beräknar Fibonacci för delat med talet). Redan för små n får man MASSOR med parallellism.
Så uppgiften denna gång är att i sitt favoritspråk jämföra hastigheten av att beräkna F(45) = 1134903170 med den enkla implementationen listad ovan med en version som kan utnyttja flera CPU-kärnor. Extra intressant blir det om man kör på 1,2,3,4... CPU-kärnor se nästa inlägg i hur man gör detta på Linux (går även att göra på Windows, ska försöka leta upp hur).
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer


