AnandTech har ju egentligen redan lurat ut svaret på deras egen fråga:
"As a brief aside, as a performance exercise we ran the tensor version of our HGEMM benchmark on the GTX 1660 Ti. And it completed?! Performance was a bit lower, at 10.8 TFLOPS versus 11 TFLOPS with tensors disabled, but it did complete. Which indicates that either NVIDIA has been less than forthcoming on TU116, or in order to keep all Turing parts on CC 7.5, they are sending tensor ops through the CUDA cores on Turing Minor cards"
Var just för att säkerställa 100 % ISA-kompatibilitet mellan alla Pascal modeller som man lade in FP16 stöd i konsumentmodellerna.
Det som inte framgått tidigare var att FP16 hanteras m.h.a. tensor-kärnorna i Turing. Då dessa är borttagna i TU-11x hade man bara valet att inte göra TU-11x ISA-kompatibel med TU-10x (vilket på många sätt vore olyckligt) eller så var man tvungen att hantera FP16 instruktioner (inklusive de för tensor-kärnorna) på ett annat sätt.
Största poängen med FP16 är ju just AI. Tensor-kärnorna är ju egentligen bara en hastighetsoptimering, med dessa får man i Volta/Turing x8 högre prestanda jämfört med att köra FP32 i SM medan AMD/Intel och nu även TU-11x får den mer förväntande prestandavinstökningen på x2.
Då TU-10x och TU-11x är ISA-kompatibel finns det egentligen inget hinder att köra saker som DLSS på TU-11x. Frågan är bara om det är värt kostnaden då det kommer ta x4 så långt tid (det innan man räknar in den lägre baskapaciteten på 1660Ti över t.ex. 2060).
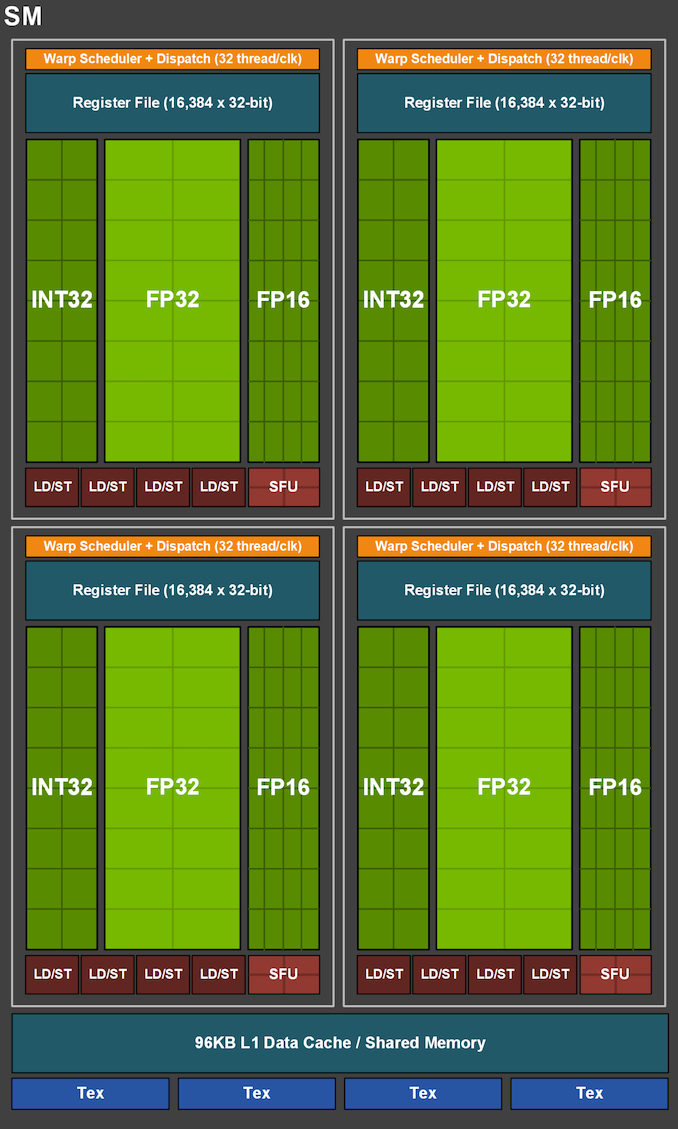
Har tidigare aldrig fått ihop det här med "parallell" körning av flyttal/heltal på Turing då en av förändringarna från Pascal är att det numera bara finns en "warp-scheduler" per SM mot tidigare två.
Detaljen jag missade var att det är ju faktiskt bara 16 st FP32 och 16 st INT ALUs per SM, d.v.s. det tar minst två cykler att köra en instruktion då alla Nvidias "CUDA" GPUer har 32 "CUDA-kärnor" per warp (per programräknare). Däremot klarar "warp-scheduler" att starta en instruktion per cykel. Vad det handlar om är egentligen bara att det finns tre "issue-portar", en för INT, en för FP32 och en för tensor(TU-10x)/FP16(TU-11x).
Pascal och tidigare var superskalära, där kunde upp till två instruktioner per cykel startas per cykel. Givet IPC ökningen i Turing var det uppenbarligen bättre att öka latensen genom att kräva två cykler per instruktion, kunna nästan dubbla antalet SMs vid en viss transistorbudget då det i Turing bara behövs hälften så många ALUs för att upprätthålla fyra "warps" per SM (fast här verkar det mesta av vinsten i stället lagts på tillägg av tensor-kärnor).
GCN gör ett liknande "trick". Där är en "wave-front" 64 trådar bred men ALUs hanterar bara 16 trådar per cykel. För att nå full effektivitet krävs därför minst fyra separata "wave-fronts" då GCN front-end också kan starta en instruktion per cykel (finns totalt 4 st ALUs som alla kan hantera 16 trådar per cykel), men till skillnad från Turing kan bara var 4:e instruktion komma från samma tråd, instruktion N, N+1, N+2 och N+3 måste komma från olika "wave-fronts".
Intressant hur nästan samma idé kan ge så olika effekt på "IPC". Djävulen är verkligen i detaljerna här!
Allt ovan skrivet: det försvarar ändå inte att 1660Ti har samma prestanda/pris som 2060. 2060 har bättre prestanda/pris jämfört 2070 som har bättre prestanda/pris jämfört med 2080. Det är vad man förväntar sig, 1660Ti borde därför vara billigare än de 3250 kr vi nu ser då det finns 2060 från ~4000 kr.