Det stämmer, jag avsåg 8700k vs 2700X. 1 är förövrigt den multiplikativa identiteten.
Ja, det är från AnandTech.
Det är begging the question att hävda slutsatsen i premisserna, men jag har inte tittat på deras förklaring (Win 8 timings igen?), ska kika, men huruvida Dolphin är en entrådad last är väl inte omtvistat?
Som jag har förstått det, rätta mig gärna, är emuleringen av exekveringsenheter som exekverar en seriell last, som i Dolphins fall, både processorintensiv och av sin natur entrådig, att fördela lasten kan bara gå långsammare tack vare synk, och att det därför krävs kort period - högre ipc - och hög frekvens på en ensam processorkärna. Frekvenshöjning är även poänglöst om instruktionen inte utförs under en period. Moderna emuleringsplattformar kan göras flertrådiga tack vare fullständig interruptuppsättning och att lasten på gästsystemet i sig är flertrådig. Detta vid realtidskrav. Eller?
Som jag också har förstått det med tanke på QEMU är att det finns fler register i 64-bit och att således 64-bit i sig är en prestandavinst utöver det ökade omfånget på minnessadressering?
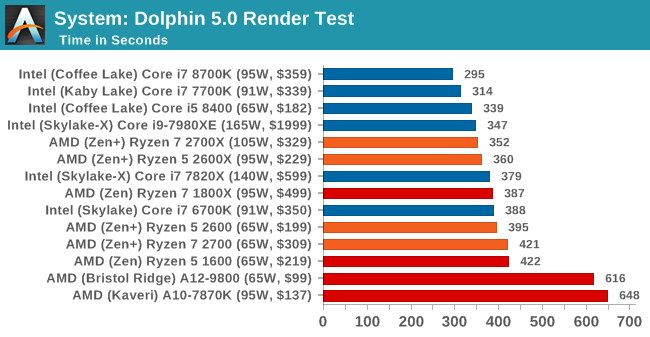
Dolphin benchmark är tyvärr som rätt andra benchmarks: rätt orealistiskt. Detta då den inte testar det nästan alla använder Dolphin till, d.v.s. köra spel, utan benchmark kör "POV-Ray" benchmark emulerat.
Finns att ladda ner här. Kör jag den på min Surface 4 drar det väldigt nära 100 % på alla fyra CPU-trådar. Lite analys med Microsoft process explorer visar att det är 5-6 trådar som är aktiva, men majoriteten av lasten ligger på två CPU-trådar.
Vilket fortfarande gör AnandTechs relativa prestanda mellan i7-6700K och i7-8700K väldigt märklig, det är något som inte alls står rätt till där. Felet var ju att AnandTech tvingade in användning av HPET. Ett stort problem med HPET är att det krävs systemanrop för varje avläsning, vilket gör tidsmätningar med HPET långt dyrare jämfört med RDTSC instruktionerna (som just är x86-instruktioner och därmed inte kräver systemanrop).
Intel drabbas dubbelt av HPET. Dels har Intel högre noggrannhet i HPET, specifikationen säger minst 10 MHz (100 ns upplösning), vilket är vad AMD kör med. Men Intel har valt 24 MHz (42 ns upplösning), något som ökar antalet systemanrop för att ladda om HPET. Sedan blev systemanrop dyrare i.o.m. Meltdown-patcharna, fast RDTSC påverkar överhuvudtaget inte av dessa.
Angående ARM 32 vs 64 bitars. Det går överhuvudtaget inte att jämföra med andra övergångar till 64-bitars. Aarch64 har lika mycket gemensamt med 32-bitars ARM som det har med PowerPC eller MIPS. Normalt blir det långsammare att köra 64-bitars kod.
x86_64 var ett undantag då man ökade antal register och fixade lite andra grodor (vettig PC-relativ adressering), i samband med övergången. Men på det stora hela är x86_64 rätt mycket bara en utökning av 32-bitars x86.
Precis som x86 är 32-bitars ARM en rejäl soppa av historiska beslut som idag är långt ifrån optimalt. Så ARM bestämde helt sonika att starta med ett blankt papper och göra om hela ISA från scratch. Nu är Aarch64, tillsammans med RISC-V, de enda två "perfekta" ISA som existerar givet dagens krav på programvara.
Ska bli väldigt spännande att se hur stor fördel detta blir i praktiken. De rena Aarch64 designer som finns idag (Apples senare CPUer, Qualcomm Falkor samt Caviums ThunderX2) presterar faktiskt helt imponerande, de är helt i nivå med high-end x86 samtidigt som de fortfarande använder färre transistorer och är något mer strömeffektiva.
Care About Your Craft: Why spend your life developing software unless you care about doing it well? - The Pragmatic Programmer