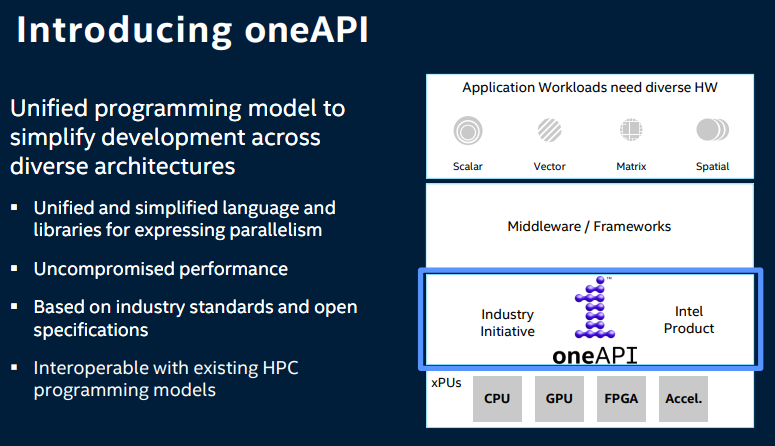
Just nu finns egentligen bara ett realistiskt val för professionellt bruk: CUDA. Till om med AMD verkar för tillfället tycka att CUDA + deras HIP-projekt som man konvertera CUDA till något som man köras på GCN/RDNA är vad man primärt bör välja, OpenCL har man i praktiken gett upp.
Intel är ju de enda som verkar ha någon form av relevant satsning på OpenCL just nu. Vill kan köra något över lite fler enheter är man i praktiken fast på OpenCL 1.2. 2.x stödet är utanför Intels prylar rätt risigt och OpenCL SPIR-V stöd verkar vara helt Intel specifikt för tillfället. Men egentligen kvittar det, OpenCL är allt för komplicerat att använda jämfört med CUDA samtidigt som CUDA i praktiken är enklare att skriva saker som presterar väl i, så varför välja något annat?
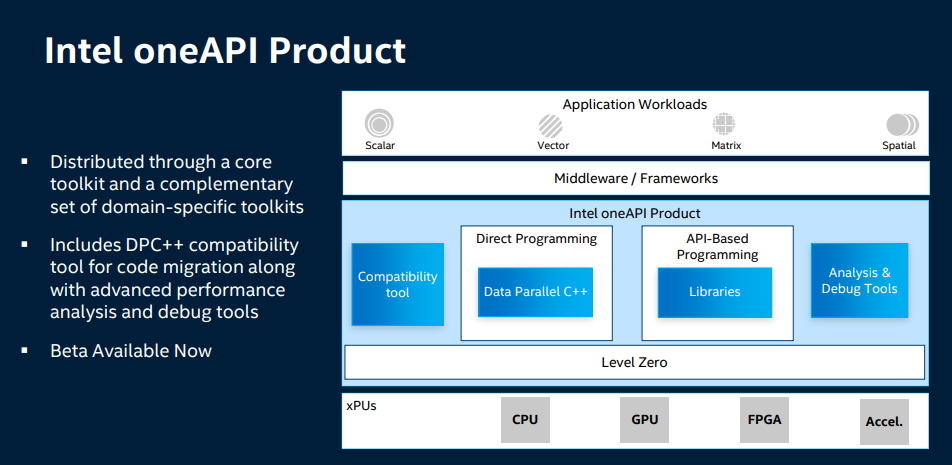
För den som vill titta finns en beta att ladda ned, har inte haft tid att kolla själv.
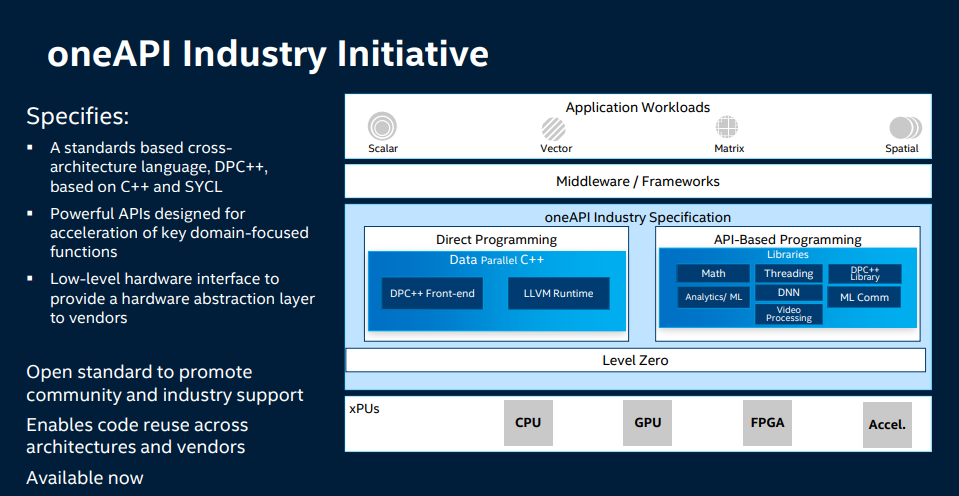
Edit: var tvungen att snabb kolla i alla fall ett exempel i oneAPI. Verkar som det är SYCL som används som motsvarighet till CUDA på Nvidia GPUer.
Inte helt med på varför Khronos presterar SYCL som "C++ Single-source Heterogeneous Programming for OpenCL". Som jag förstått SYCL specifikationen så är det ju ett separata API. Det är dock designat så att man kan välja att implementera sitt SYCL ramverk ovanpå OpenCL (vilket är exakt hur Intel implementerar SYCL och deras tool-chain hittar man här). D.v.s. mer eller mindre använda OpenCL som "driver API" under huven.
AMD använder ju sitt HIP-projekt även för SYCL stöd, HipSYCL. HipSYSL har också stöd för SYCL med CUDA som "driver-lager" om man kör på Nvidia-kort.