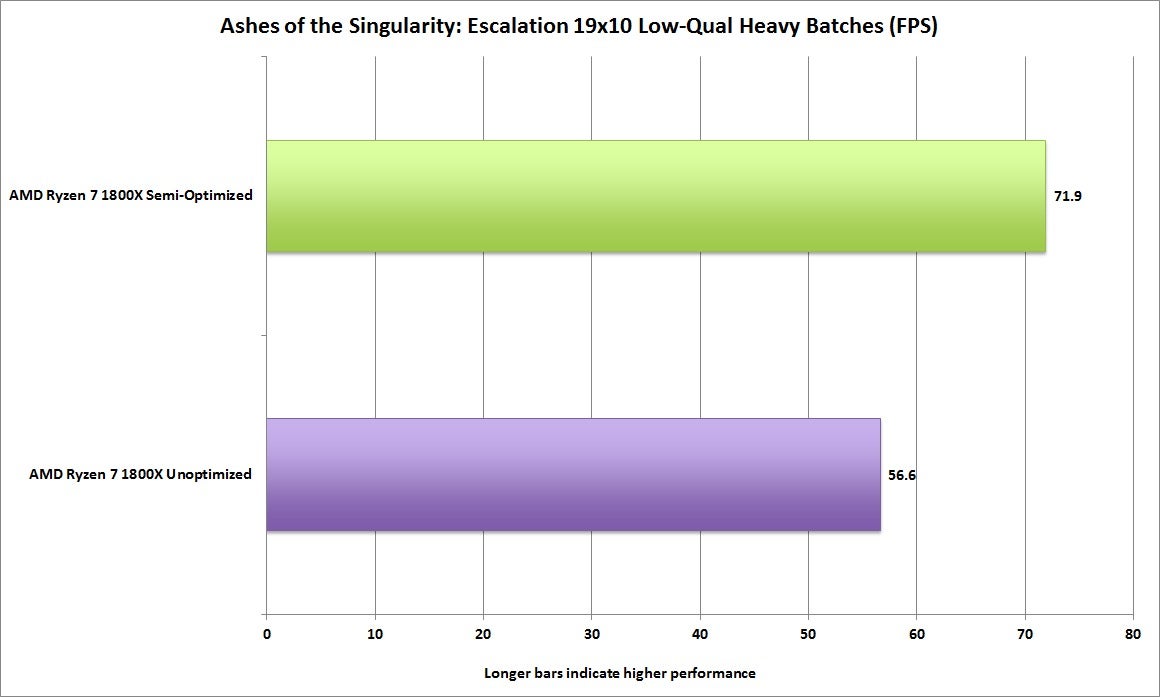
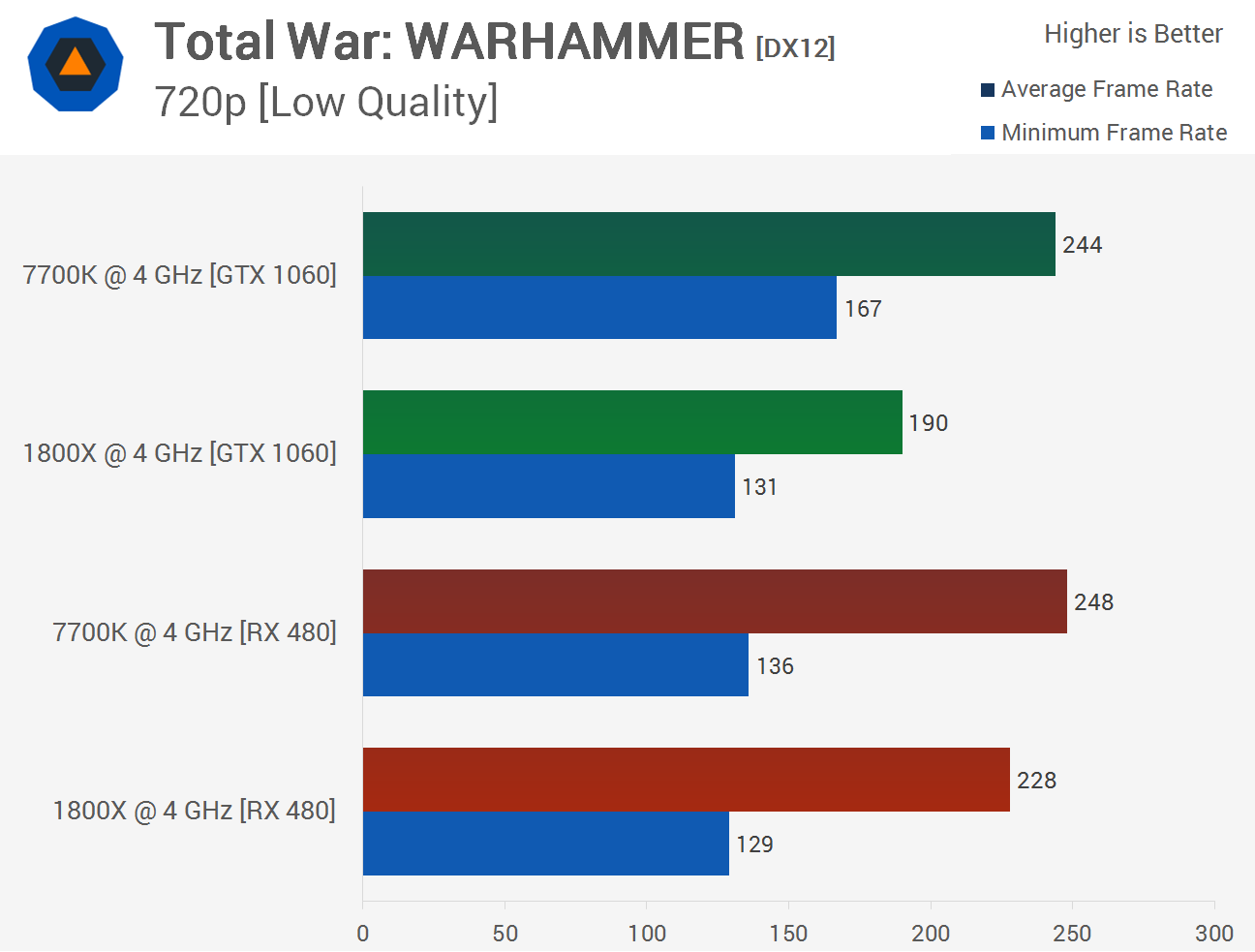
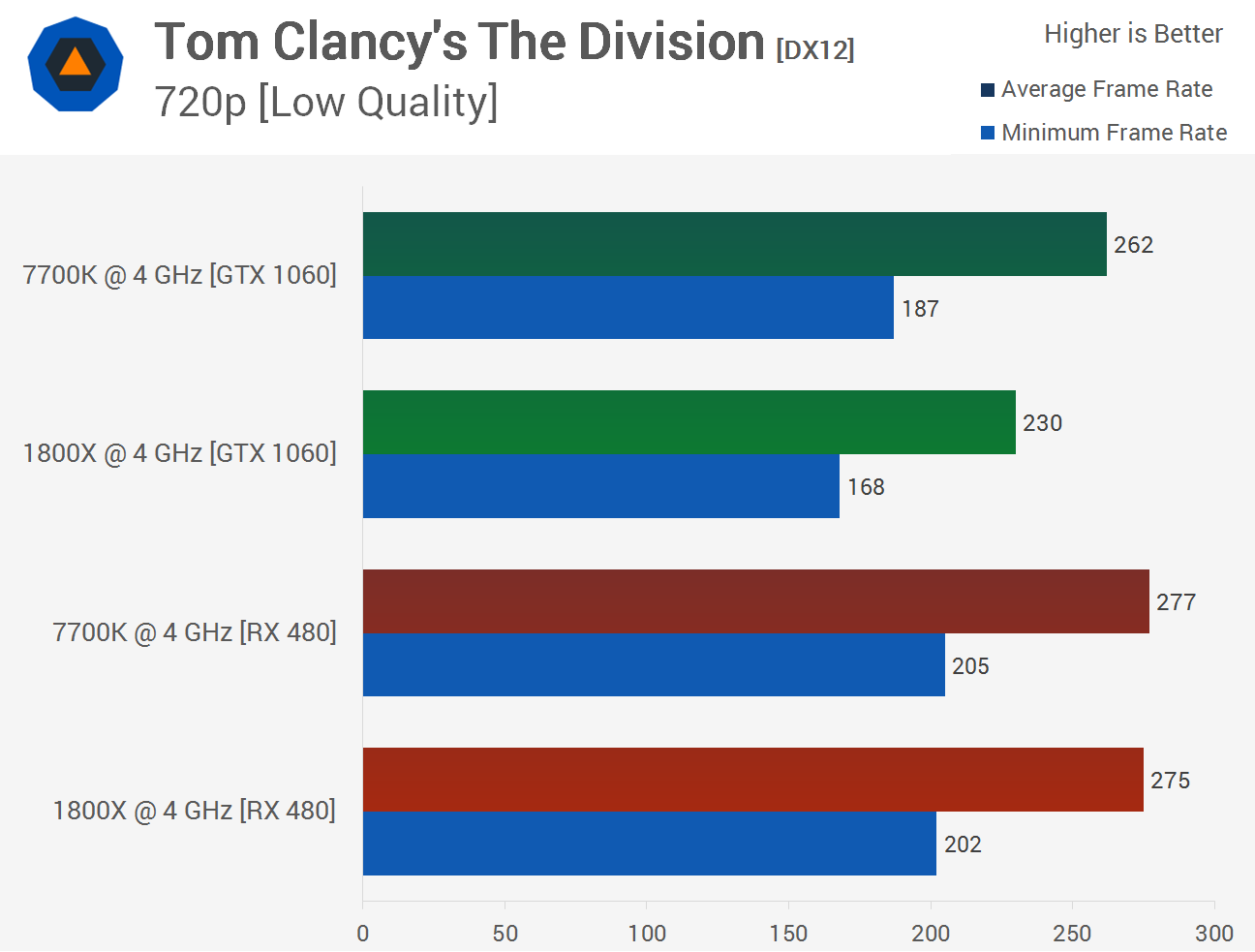
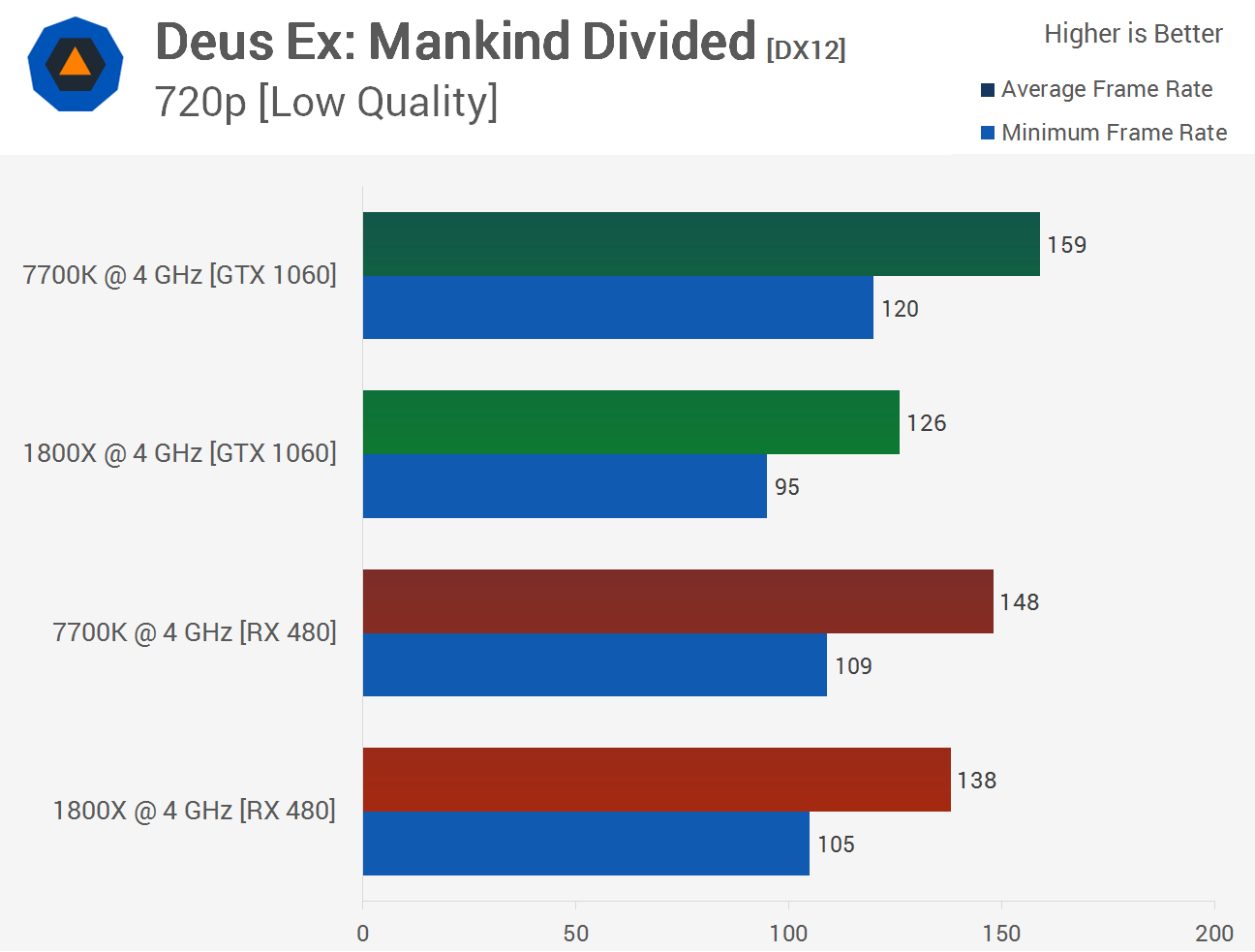
Du skrev detta tidigare
"Alltså, i 720p testerna med cpu limitering presterar nvidia sämre i dx12 än det borde relativt dx11 bara på ryzen samtidigt som detta inte händer på intel, dessutom presterar nvidia sämre relativt amd på ryzen med lägre minneshastighet även i dx11, deltat mellan rx480 och 1060 ökar, med AMD gpu så sker detta inte på intel eller ryzen, deltat mellan gpuerna krymper/ökar på ett sätt som det inte ska göra, kom ihåg bägge var kraftigt cpu limiterade och fps skulle inte dykt på kombon nvidia/ryzen om allt funkar bra."
Vilket överhuvudtaget inte stämmer överens med den video du själv länkade som referens. Den relativa skillnaden mellan DX12 och DX11 är väldigt snarlik för 7700K och 1700X.
Och nu hävdar du att jag inte förstår problemet, dina svar är rätt inkoherenta med data du själv postar. Din försvar för detta är alltså att jag tydligen borde fattat att det inte var DEN videon man ska titta på utan något helt annat som tydlige visar problemet i "rätt" ljus.
På vilket sätt ursäktar jag Nvidia? Det är ett torrt konstaterande att Nvidia gör delar i programvara som AMD gör i HW. Är ju knappast någon nyhet att programvarubaserade lösningar är långt mer flexibla, men de kräver självklart med CPU-kraft då det är, well, programvara... Vad det gäller DX11 borde det vid det här laget vara rätt välkänd fakta att AMD aldrig kunnat utnyttja CGN på ett bra sätt i den APIn.
Både Nvidia (Fermi) och AMD (GCN) trodde ju väldigt hårt på att GPGPU skulle bli rejält populärt, båda dessa GPU-arkitekturer var väldigt inriktade på GPGPU (då aktuell DX-version inte kunde använda en rad funktioner man introducerade i dessa designer). Verkar som Nvidia rätt tidigt insåg att GPGPU inte kom att användas i någon relevant utsträckning på konsument GPUer, så man strippade bort dessa finesser till stor del för att kunna lägga transistorer på annat. AMD verkar ta det steget först med Vega (vi vet snart).
Hur ser det ut i argumentationen då? Peka ut vilka påståenden som är fel. Och för den delen, påverkas din trovärdighet av att du "Kör själv enbart med Intel och Nvidia"?
Själv är jag övertygad att ARM kommer "vinna" i slutändan, jag tjänar brutalt mycket pengar på att skriva kod just för ARM system. ARM är Intels värsta fiende. Förändrar det på något sätt de fakta jag pekar på? Ser överhuvudtaget inte varför det skulle ändra något alls.
Några fakta som tydligen sticker i ögonen och enligt dig gör det väldigt svårt med trovärdigheten:
Spel jobbar främst med skalära heltal, Skylake har ~40 % högre IPC där jämfört med Zen. Går bl.a. att se i WebXPRT (enkeltrådat) och kompilering (perfekt skalning över kärnor).
Spel skalar inte i närheten perfekt med ökande antal CPU-kärnor
Nvidia gör mer i programvara jämfört med AMD på GPU-sidan, system med Nvidia GPUer kommer därför tidigare bli CPU-bundna
Vad av ovan är skrämmande kontroversiellt att det tydligen helt äventyrar min trovärdighet?
Om ovan ändå kan accepteras som att vara korrekt: är inte det överlägset enklaste förklaring för de observationer vissa youtuber då gjort helt enkelt att om man gör ett spel CPU-bundet så kommer 7700K prestera bättre då en 7700K i stock är ~50 % starkare per CPU-kärna jämfört med Ryzen 7 @ 4,0 GHz?
Då AMD gör mer i HW kommer man bli CPU-bunden vid högre FPS.
Att det inte krävs en fullskalig komplott mot datorvärldens Messias verkar för vissa vara en total omöjlighet.
Det som gör den teorin rätt osannolik, d.v.s. Nvidia sprider ut arbete för DX12, är ju att det finns en rad officiella uttalande från Nvidia som säger att applikationen måste göra all form av balansering mellan CPU-kärnor i DX12 för drivern kommer aldrig skapa egna trådar. Varför skulle det fungera på något annat sätt än vad Nvidia hävdar i sina egna optimeringsguider?
Vad är det för fel på den betydligt mycket enklare förklaringen ovan? Eller konspirerar kompilatortillverkare och de som tillverkar webbläsare också mot AMD.
OBS: säger inte att det finns optimeringar att göra som kan gynna Ryzen, säger bara att de resultat kring DX12 som presenteras känns ju så uppenbart enkla att förklara om man bara accepterar att Nvidias GPUer är designande på ett sätt som gör dem mer beroende av en snabb CPU + Ryzen har inte alls lika bra IPC relativt Core-serien när det handlar om skalära heltal som den har för skalära flyttal, spel använder nästan bara skalära heltal.